| REGION | COUNTRY | YEAR | POP | TOTAL Actual DD | Actual DBD | Actual DCD |
|---|---|---|---|---|---|---|
| Africa | Zimbabwe | 2013 | 14.1 | NA | NA | NA |
| Europe | Serbia | 2015 | 8.9 | 41 | 41 | 0 |
| Europe | Switzerland | 2006 | 7.3 | 80 | NA | NA |
| Europe | Bosnia and Herzegovina | 2015 | 3.8 | 6 | 6 | 0 |
| Europe | Sweden | 2006 | 9.1 | 137 | NA | NA |
| Africa | Botswana | 2003 | 1.8 | NA | NA | NA |
| America | Argentina | 2001 | 37.5 | NA | NA | NA |
| Western Pacific | Cook Islands | 2002 | 0.0 | NA | NA | NA |
| Europe | Belgium | 2011 | 10.8 | 331 | 267 | 64 |
| Europe | Estonia | 2003 | 1.3 | 14 | 14 | NA |
4 Data Preparation
This is the Open Access web version of Veridical Data Science. A print version of this book is published by MIT Press. This work and associated materials are subject to a Creative Commons CC-BY-NC-ND license.
Every data science project arises from a real-world question whose answer is believed to lie (in part) within some data that either has been or will be collected. Perhaps your question is: Which house should I buy? To answer this question, you might plan to analyze some data containing information on recent housing sales in your city, where, for each house sale, the data might contain information including how large the house is, what kind of condition it is in, when the house was sold, and how much the house sold for. Your eventual decision about which house to buy might then be based on a combination of your analysis of this data and your domain knowledge about houses and the city in which you live (and your preferences, of course!).
Whatever your question, chances are that the data that you have access to will need to be modified to answer it. Datasets are thoroughly irregular creatures. Datasets collected in the real world will often contain mistakes and ambiguities (such as a house whose size is incorrectly reported to be \(200\) square feet when it was actually supposed to be \(2,000\) square feet) and are often formatted inconveniently (such as information from houses in different neighborhoods being spread across multiple tables). These issues can cause you—and subsequently, your computer—to misinterpret the data, potentially resulting in misleading conclusions.
Fortunately, some data issues are redeemable. With an understanding of where the data came from and how it was collected, you can fix unclear column names, extract the relevant portions of text entries, and convert the dataset to a format that is easier to work with. This process is called data cleaning. Unfortunately, however, not all issues are redeemable. For instance, there may be mistaken entries in your data that will lie undetected unless the offending entries themselves are “impossible.” For example, suppose that a house sale date entry is incorrectly reported as May 15 when the house was actually sold on March 15. Since May 15 is a perfectly plausible date, there is no way to identify that the date is incorrect unless it is inconsistent with some other information recorded in the data. In most cases, there is no way to ensure that every value in your data is correct without manually double-checking that every value matches the real-world quantity that it is supposed to measure (a task that is usually impossible, especially if the quantity being measured is transient).
For redeemable issues that you can identify, there are often multiple reasonable ways to remedy them, and the decision that you make will typically involve a judgment call. For instance, imagine that some of the houses in the housing sales dataset have a reported “date of sale” entry with impossible values, such as a month value of “13” (as far as we know, there is no thirteenth month!). How might you fix or clean these values? One way might be to convert all impossible month entries to explicitly missing values (e.g., replace them with NA), and another might be to convert them to a particular date, such as January 1. Each of these cleaning judgment call options would create a slightly different “clean” version of the data, which in turn may lead to slightly different downstream results and conclusions.
Making judgment calls when working with data is unavoidable. It is thus very important to keep a record of the data cleaning judgment calls that you make, as well as the alternative judgment calls that you could have made so you can explicitly investigate their potential impact on your downstream results. In veridical data science, we recommend doing this by encapsulating your data cleaning (and preprocessing—see below) procedure in a reusable function that includes the alternative judgment call options as arguments (making it easy to create alternative versions of the cleaned data), as well as documenting the judgment call options in the relevant data science life cycle (DSLC) documentation files.
Since data cleaning involves modifying your data, a word of warning is needed: never modify the raw data file itself. Instead, write code that will only modify the version of your data that you have loaded into your programming environment. Unless you explicitly export and save the modified data object as a file with the same name as the raw data file, any changes you make in your programming environment won’t overwrite the original file.
Although data cleaning is rarely the star of the data science show, the process of data cleaning forms the bedrock of every data science project, and will often take up to 50 percent to 80 percent of the entire time spent on the project! However, although data cleaning is arguably the most important stage of the DSLC—and is also the one that typically takes the most time—it is also the stage that is the least often taught or discussed.
Unfortunately, this is partly because the process of data cleaning is extremely hard to automate because it can end up looking quite different from one dataset to another. The process of determining how a dataset needs to be cleaned involves a human physically looking at the dataset and using critical thinking skills and domain knowledge to determine the ways in which the data is incorrect, ambiguous, or needs to be reformatted. An automated system won’t know that for a particular medical survey dataset, a value of “99” actually means “declined to answer,” or that for a house price dataset, a house quality rating of “fair” is considered to be worse than a rating of “typical.” Data cleaning is a challenging task that must be guided by a human who has a reasonable understanding of both the background domain and the data collection process itself.
Since data cleaning involves obtaining a detailed understanding of your data and its limitations (in the context of the domain problem), this stage is one of the most informative parts of the DSLC. As a result, if you don’t have access to the raw data or if you offload the data cleaning stage to someone else1, you may lose out on obtaining many of the intricate understandings of the data that are typically only learned through the process of examining it and preparing it for analysis.
Despite how important this stage is for every data science project, there is unfortunately no universal set of data cleaning steps that you can directly apply to every dataset. Every project and every dataset are unique, so no two data cleaning procedures will look the same. In this chapter, we will introduce some common traits of “messy data” that you can look out for, and outline how to develop a customizable data cleaning procedure that involves learning about the relevant background domain information and the data collection process, exploring the data, and using the insights obtained to create a specific set of data cleaning “action items.” The goal of this chapter is to bring some clarity, structure, and hopefully some excitement, into the investigative journey of the data cleaning process.
While the process of data cleaning involves reducing ambiguities in your data and converting it to a more usable (e.g., “tidy”) format, it is not designed to prepare your data for the application of a specific algorithm or analysis. However, many algorithms have specific formatting requirements. For instance, some algorithms don’t allow missing values, some require all variables to be numeric, and others assume that all the variables are on the same scale. Your data can be “clean” but still not satisfy the formatting requirements of the specific algorithms that you seek to apply.
The process of further modifying your clean data to fit a particular algorithm or analysis is called preprocessing. Preprocessing may involve imputing missing values, converting categorical variables to numeric formats, or featurization, which is the process of creating new features/variables by applying transformations to the original features. Like data cleaning, preprocessing typically involves making judgment calls (such as whether to impute missing values using the mean or the median or whether to apply a logarithmic or a square-root transformation to the features), all of which should be clearly documented.
Just as with data cleaning, we recommend writing a preprocessing function that can be used to create alternative versions of your preprocessed dataset, not just to evaluate the stability of your downstream results to the judgment calls that you made at this stage, but also so that you can easily create alternative versions of your preprocessed dataset that are formatted for multiple different algorithms without having to duplicate your code.
We thus define the overall process of data preparation as a two-stage procedure that involves: (1) cleaning your data by modifying it so it is appropriately formatted and unambiguous, and (2) preprocessing your data so it conforms to the formatting requirements required by whatever computational algorithms you plan to use to answer your question.
It is worth noting that data cleaning and preprocessing are often conflated, with no distinction between them. The two processes are indeed very similar and often overlap. For some applications, it may be neater to write one single data preparation function that both cleans and preprocesses the data and whose arguments include both data cleaning and preprocessing judgment calls (essentially conflating the two processes), whereas, for other applications, it might make more sense to keep the two processes separate by writing two different functions (a data cleaning function and a preprocessing function). The choice of how to structure your data cleaning and preprocessing is up to you and may vary from project to project.
Since preprocessing is specific to the algorithms that you will be implementing (and we have yet to introduce any algorithms), this chapter focuses on the more general process of data cleaning.
4.1 The Organ Donation Data
Throughout this chapter, we will place ourselves in the shoes of a journalist who is interested in identifying which countries have demonstrated an increase in organ transplant donation rates over time, as well as which countries have the highest organ donation rates. To begin answering these questions, we need data. Since it is unrealistic for us to conduct a worldwide survey on transplantation practices, we will instead use publicly available survey data from the Global Observatory on Donation and Transplantation (GODT) that was collected in a collaboration between the World Health Organization (WHO) and the Spanish Transplant Organization, Organización Nacional de Trasplantes (ONT). This database contains information about organ donations and transplants (a total of 24 variables/columns) for 194 countries based on an annual survey that, according to the GODT website, began in 2007. We will consider a version of the data that contains information up to 2017. Table tbl-organs-random displays 10 randomly selected rows and the first 7 columns2 of the organ donation data. Notice that there are many missing values, which are coded as NA.
Keep in mind that this is public data, and we are not personally in communication with the people who collected it. All the information that we possess about the data comes from the information provided on the website and our existing domain understanding. As a result, many questions will arise and we will make many assumptions throughout our examination of the data that we will be unable to answer or check. This doesn’t mean that we can’t learn a lot from this data, but it does mean that we don’t know exactly how strong the link between the data and reality is.
The data and the relevant documentation and code for this chapter can be found in the organ_donations/ folder of the supplementary GitHub repository.
4.1.1 A Plan for Evaluating Predictability
Once we generate some results, we will want to scrutinize them using the principles of predictability, computability, and stability (PCS). Since demonstrating predictability may involve collecting more data, splitting your current data into training, validation, and test sets, or collecting some reputable domain evidence that agrees with your results, it is important to make a plan for demonstrating the predictability of your results before working with the data.
Since this project is exploratory in nature (our goal is to explicitly summarize the organ donation trends of all countries across all years), we are hesitant to withhold any of our data from our explorations. For this project, we thus plan to examine the predictability of our findings by consulting the domain literature on global organ donation trends to see if they match what we find in our explorations.
Note that an alternative approach might involve collecting more recent data from the GODT website (e.g., via the “Export Database” page at http://www.transplant-observatory.org/export-database/)—or even better, from an alternative data source—and confirming the trends and patterns that we identify reemerge in the additional data source.
4.2 A Generalizable Data Cleaning Procedure
While there is no one-size-fits-all data cleaning formula to follow, this section will introduce some general principles that can help guide you through your data cleaning journey, using the organ donation data as an example. The data cleaning procedure will involve learning about the data collection process, obtaining domain knowledge, examining the data, asking and answering questions, checking assumptions, and identifying and documenting any issues and inconsistencies to create a set of custom data cleaning action items.
Action items are customized modifications (such as converting ordered categorical values to numbers), that you will need to apply to your data to clean it. Often an action item will involve multiple judgment call options. Once a set of action items have been identified, we recommend writing a function that will take the original dataset as the primary input and the judgment call options as additional arguments and will implement the relevant action items to create the cleaned data as the output.
The four-step data cleaning procedure (Figure fig-data-cleaning-diagram) involves:
Step 1: Learn about the data collection process and the problem domain. If you start looking at the data before having at least a general sense of how the data was collected and what the data is supposed to contain, you run the risk of making incorrect assumptions about what the data is capturing. Read all available supplementary documentation and codebooks thoroughly, seeking additional information if needed. Talk to domain experts and, if possible, try to physically observe the data being collected and talk to the people who collected it. Ensure that you have at least a basic level of background domain understanding (e.g., if you are working on a project whose goal is to diagnose melanoma from images, take some time to learn about melanoma and the imaging process).
Step 2: Load the data. Load your data into R or Python. This may involve joining several tables together or removing irrelevant information.
Step 3: Examine the data and create action items. By exploring the data, you will start to get a general sense of its structure and what it contains. This stage will be fairly involved, and we will provide many suggested explorations in sec-examine-clean. Check that what you learn from the domain experts and your own explorations matches what you learned from the background information and data documentation. Document and answer any specific questions that arise and check any assumptions that you find yourself making. Write down any appropriate action items (data cleaning or preprocessing tasks) that you identify throughout your examination of the data.
Step 4: Clean the data. Write a data cleaning function that applies the action items to the original data and returns the cleaned data. For action items that involve making a judgment call, the judgment call options should be included as function arguments.

While the data cleaning process is designed to uncover data cleaning action items, it will inevitably also uncover several preprocessing action items that you may want to implement before applying a particular algorithm (but are not required for the data to be considered “clean”). You may thus also want to write a preprocessing function at this stage (you can write two separate data cleaning and preprocessing functions, or one function that both cleans and preprocesses your data).
If you split your data into training, validation, and test sets, note that your data cleaning and preprocessing procedures should be based on the training data, but you will also need to apply the same procedures to the validation/test sets that you will be using for evaluation. However, applying some data cleaning/preprocessing action items (such as “remove variables/columns with more than 50 percent of their values missing”) directly to future data or validation/test sets can lead to datasets that are incompatible with the training data (e.g., if future/validation/test sets have slightly different patterns of missing data). To avoid this issue, while your data cleaning procedure should be defined using the training dataset, the explicit set of cleaning/preprocessing modifications that were applied to the training set then should be applied to the future/validation/test sets (e.g., if your missing value threshold of 50 percent choice resulted in the removal of columns X, Y, and Z from the training data, then you should remove these same columns X, Y, and Z from the future/validation/test sets, even if they didn’t meet the same missing value threshold criteria for the future/validation/test).
The remainder of this chapter will expand on each step of this data cleaning procedure, providing examples in the context of the organ donation project.
4.3 Step 1: Learn About the Data Collection Process and the Problem Domain
The purpose of this first step of the data cleaning procedure is to learn what each variable is designed to measure, how each variable was collected, and what the observational units in the data are.
Start by learning about the domain area (e.g., via the internet, reading books and journal articles, and talking to domain experts), reviewing any documentation that was provided with the data, and talking to the people who collected the data (if possible). Be sure to document the relevant background information in your documentation files, try to answer any questions that arise, and check any assumptions that you find yourself making about how the data was collected and what its values are measuring. Try to resist blindly accepting what the data documentation (such as codebooks or descriptions of the data) tells you; always check (to the best of your ability) that the information provided matches what you find in the data.
Box box-background contains some suggested questions that you can ask while reviewing the background and domain information.
4.3.1 Reviewing the Background and Domain Information of the Organ Donation Data
Let’s briefly walk through the previous questions for the organ donation data. A more detailed version of the answers given here can be found in the “Step 1: Review Background Information” section of the 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository.
What does each variable measure? The part of the data dictionary provided on the WHO website that is relevant for the subset of organ donation data shown in Table tbl-organs-random is reproduced in Table tbl-codebook. Note that the numbers in the data are the reported counts rather than the actual real-world counts.
Table 4.2: The codebook describing the definition of some of the variables in the organ donation data Variable Description REGION Global region in which the country lies COUNTRY Name of the country for which the data is collected REPORTYEAR Year for which the data is collected POPULATION Population of the country for the given year TOTAL Actual DD Number of deceased donors (DD) Actual DBD Number of deceased donors after brain death (DBD) Actual DCD Number of deceased donors after circulatory death (DCD) How was the data collected? The website from which we downloaded the organ donation data states that it is based on a survey that began in 2007 and is sent annually via email to “national focal points.” For countries that have a centralized organ donation and transplantation organization, this information would likely be much easier to obtain than for the many countries that do not have well-organized transplant systems (or which have multiple donor organizations). A copy of this survey3 and some additional background documents are provided in the
organ_donations/data/data_documentation/folder of the supplementary GitHub repository. Some questions that arose include: How did the survey-takers know who to send these survey forms to? Which countries have a centralized organ donation organization?What are the observational units? For the organ donation data, the donor counts are reported every year for each country, so the observational units are the “country-year” combinations.
Is the data relevant to my project? Since we are asking about donor trends for each country over time, this data is certainly relevant.
What questions do I have, and what assumptions am I making? One example of an assumption that we made is that the brain-death deceased donors (
Actual DBD) and circulatory-death deceased donors (Actual DCD) add up to the total number of deceased donors (TOTAL Actual DD). After we loaded the data into R/Python (in the next step), we conducted some quick checks in the data to confirm that this is indeed true in all but a small number of rare cases.
4.4 Step 2: Load the Data
Loading your data into your R or Python programming environment may be as simple as loading in a .csv file with one line of code. However, sometimes you will receive data that has an unfamiliar format, has formatting issues, or is spread across various files, which will make loading the data into R or Python slightly more complex.
To identify how to load your data, you may find it helpful to ask the questions in Box box-data-loading.
Once you have loaded your data into your programming environment, you will want to check that the data object in your programming environment matches the original data file (i.e., that all the rows are included, and the values that it contains are correct and have not been corrupted upon loading). Box box-check-load lists some simple techniques for checking that your data has been loaded correctly.
4.4.1 Loading the Organ Donation Data
Fortunately, the organ donation data is very simple to load, requiring only a few lines of code. The code for loading in the organ donation data can be found in the “Step 2: Loading in the Data” section of the relevant 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subdirectory of the supplementary GitHub repository.
When we checked the dimension of the data, however, we found that it did not match what we expected from the information provided along with the data. Recall that the donation survey supposedly began in 2007. Since we are considering a version of the data that contains information up to 2017, and there are 194 countries in the data, it should contain \(194 \times 11 = 2,134\) rows. The data, however, contains \(3,165\) rows, which is not even divisible by 194! Something fishy is going on, and we made a note of it in our DSLC documentation (Question: Why does the data contain more rows than expected?). If, by the time we have completed our data cleaning explorations in Step 3, we haven’t arrived at an answer to this question, we will conduct some specific explorations to try to answer it.
4.5 Step 3: Examine the Data and Create Action Items
To determine the data cleaning action items, you first need to identify the ways in which your data is “messy.” The best way to identify messiness in a dataset is to explore it, such as by looking at subsets of the data, and by presenting summaries of the data using graphs and tables.
We recommend starting your explorations by trying to identify whether your data suffers from any of the following common symptoms of messy data:
Invalid or inconsistent values. Invalid values are usually impossible measurements. Validity is dictated by the problem domain. Inconsistent values might be identified when there are measurements in the data that disagree with other measurements.
Improperly formatted missing values. Often when a particular measurement is not available or is not properly entered, it is reported as “missing” (
NA) in the data. While a clean dataset may contain missing values, they should be explicitly formatted asNAin R (orNaNin Python), rather than as arbitrary numbers, such as999, or arbitrary categorical levels, such as"unknown".Nonstandard data format. It is typically easiest to work with data that conforms to a standard “tidy” format, where each row corresponds to the data for a single observational unit and each column corresponds to a unique type of measurement.
Messy column names. Your variable column names should be meaningful to the humans who will be reading them and should follow a consistent style guide (e.g., use underscores rather than spaces or periods to separate words as per the style guide introduced in sec-code-guidelines of sec-workflow-setup).
Improper variable types. Each variable should have an appropriate type (e.g., numeric, character, logical, date-time, etc.) based on what the variable is measuring and how you want it to be interpreted.
Incomplete data. Data for which every observational unit appears exactly once (i.e., none are duplicated and none are missing from the data) is considered complete. For instance, in the organ donation data, every country should have exactly one row per year in the data.
Next, we will expand on each of these common messy data traits and provide some more details on how to identify them, as well as some recommended action items for cleaning them. Feel free to follow along with the code in the “Step 3: Examine the Data and Create Action Items” section of the 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository. Note that once you have finished with these explorations, there may be additional data-specific explorations that you want to conduct.
4.5.1 Messy Data Trait 1: Invalid or Inconsistent Values
One of the most common symptoms of messy data is invalid values. Invalid values can be detected if they fall outside some predetermined allowable range (e.g., a donor count of \(-10\) is impossible because donor counts should be nonnegative). What is, and is not, considered valid is dictated by domain knowledge.
How should you handle an invalid donor count of \(-10\)? Should you leave it alone, round it up to \(0\), or perhaps replace it with the previous year’s donor count? This will come down to a judgment call, which should be based on how you will be analyzing the data (and thus is more related to preprocessing than data cleaning) and informed by knowledge of how the measurement was collected (e.g., perhaps it was a manual data entry error).
Note that a strange or unexpected value that is still within the realm of possibility shouldn’t be automatically treated as invalid. For instance, if a country reported substantially more organ donations in one year than any other year (e.g., they reported 1,000 donations when they usually report only a few hundred), this measurement is unexpected but not necessarily invalid (although it would be a red flag that should initiate further investigation). Only after trying to determine whether a strange or unexpected value is actually invalid (e.g., by doing some external research or asking the people who collected the data) should you consider modifying it.
Inconsistent values might occur when there are measurements in the data that disagree with other measurements. An example would be if the number of deceased donors (TOTAL Actual DD) is greater than the reported population. Another type of inconsistency might occur when the values within a variable have different units. For instance, if a country typically reported its raw annual donor counts, but one year decided to report its donor counts per million people, then these measurements are inconsistent. As with invalid values, handling these inconsistencies will involve making a judgment call that is informed by your understanding of the data collection process and domain knowledge.
4.5.1.1 Suggested Examination
Every variable will have its own set of validity and consistency checks that should be devised based on your domain understanding of what each variable is supposed to measure and how it was collected. Some suggested examinations that can help uncover invalid or inconsistent values are listed in Box box-identify-invalid.
4.5.1.2 Possible Action Items
When you do find seemingly impossible values in your data (such as a body temperature entry of over \(1,000\) degrees Fahrenheit, an age entry of over \(200\), or a country’s organ donor count of \(-150\)), you need to decide how to handle it. Some examples of possible data cleaning action items that you might want to implement to fix invalid or inconsistent values are listed in Box box-action-invalid.
Your choice of which action items to implement will be a judgment call, each of which would lead to a different version of the clean dataset (you may include multiple options as arguments of your data cleaning function). You should document the judgment call options that you deem to be reasonable in your DSLC documentation files.
4.5.1.3 Identifying Invalid Values in the Organ Donation Data
In this section, we will conduct the suggested explorations for the organ donation data. A more detailed version of the explorations given in this discussion can be found in the supplementary GitHub repository. See the “Finding Invalid Values” section of the 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository.
Table tbl-organs-america displays the first seven columns of the donor data for the US, and Table tbl-organs-summary presents the minimum, mean, and maximum, values (ignoring missing values) for each variable. The range of each of the donor count variables seems fairly plausible (there are no negative counts, and there are no obnoxiously large counts). The population values, however, range from \(0\) to \(1,394\), which is obviously incorrect. Putting our critical thinking hats on, it seems fairly likely that the population values have been scaled. How might you figure out what scale the population counts are on? Hundreds of thousands? Millions? By comparing the population reported in the data with external population data for several countries, it seems that the population measurements have been scaled by 1 million (i.e., a population recorded as 100 is actually 100 million). If you’re working with the data yourself, as a reality check, you should check that this is true for a country of which you know the population. Since we might want to avoid potential confusion (and we might want to do some calculations relative to population later), we decided to introduce a data cleaning action item: multiply the population variable by 1 million.
| REGION | COUNTRY | YEAR | POP | TOTAL Actual DD | Actual DBD | Actual DCD |
|---|---|---|---|---|---|---|
| America | USA | 2000 | 278.4 | 5,985 | 5,852 | 118 |
| America | USA | 2001 | 285.9 | 6,080 | 5,911 | 167 |
| America | USA | 2002 | 288.5 | 6,190 | 5,999 | 190 |
| America | USA | 2003 | 294.0 | 6,457 | 6,187 | 270 |
| America | USA | 2004 | 297.0 | 7,150 | 6,757 | 393 |
| America | USA | 2005 | 298.2 | 7,593 | 7,029 | 564 |
| America | USA | 2006 | 301.0 | 8,017 | 7,375 | 642 |
| America | USA | 2007 | 303.9 | 8,085 | 7,294 | 791 |
| America | USA | 2008 | 308.8 | 7,989 | 7,140 | 849 |
| America | USA | 2009 | 314.7 | 8,022 | 7,102 | 920 |
| America | USA | 2010 | 317.6 | 7,943 | 7,000 | 943 |
| America | USA | 2011 | 313.1 | 8,126 | 7,069 | 1,057 |
| America | USA | 2012 | 315.8 | 8,143 | 7,036 | 1,107 |
| America | USA | 2013 | 320.1 | 8,269 | 7,062 | 1,207 |
| America | USA | 2014 | 322.6 | 8,596 | 7,304 | 1,292 |
| America | USA | 2015 | 321.8 | 9,079 | 7,585 | 1,494 |
| America | USA | 2016 | 324.1 | 9,970 | 8,286 | 1,684 |
| America | USA | 2017 | 324.5 | 10,286 | 8,403 | 1,883 |
| Variable | Min | Mean | Max |
|---|---|---|---|
| YEAR | 2000 | 2007.7 | 2017.0 |
| POP | 0 | 35.2 | 1393.8 |
| TOTAL Actual DD | 0 | 310.7 | 10286.0 |
| Actual DBD | 0 | 289.5 | 8403.0 |
| Actual DCD | 0 | 38.9 | 3298.0 |
Does anything else in Table tbl-organs-america seem strange? If you’ve been paying attention, you might recall that the background information indicated that the survey started in 2007. Why then does our data contain years that go back as far as 2000? Perhaps this explains why our data contains more rows than we expected, but a quick calculation implies that with 18 years of data and 194 countries, we should have \(18 \times 194 = 3,492\) rows, which is more than the 3,165 rows in the data.
How much trust should we put in the pre-2007 data? We should at least make a note of the ambiguity of the pre-2007 data, and in the meantime, we can add another data cleaning action item: add an option to remove the pre-2007 data (but have the default judgment call option be not to remove this data).
4.5.2 Messy Data Trait 2: Improperly Formatted Missing Values
Missing values typically occur in data when a measurement is not entered properly or its value is unknown. Note that a dataset can contain missing values and still be considered clean.
One of the goals of data cleaning is to ensure that the data represents reality as accurately as possible. Although it is considered a common data cleaning task, the act of removing rows with missing values may unintentionally have the effect of making the dataset less reflective of reality. This is because the very fact that the values are missing may hold meaning, and removing them may introduce bias into your data. To understand why, consider what would happen if you simply removed all the countries in the organ donation data that have any missing donor counts. In practice, this would likely correspond to removing the countries that don’t have a well-organized organ transplant system (and thus do not always report their organ donation data). As a result, any conclusions drawn from your data will no longer be relevant to all countries, just those with a well-organized organ transplant system (i.e., your data is now biased). While biases can also arise when imputing missing values (replacing missing values with plausible non-missing values), these biases are generally less severe.
Rather than aiming to explicitly remove or impute missing values, our goal at the data cleaning stage is to ensure that missing values are appropriately formatted, such as by replacing ambiguous numeric placeholders (e.g., 999) or categorical placeholders (e.g., "unknown") for missing values with explicit missing values (NA). Rarely should you remove or impute missing values during data cleaning.
That said, many algorithms that you will encounter later in this book (and outside of this book) do not accept data with missing values. When it comes to preparing your data for a particular algorithm, it may thus become necessary to impute or remove missing values. The process of imputing or removing observations with missing values in preparation for applying such an algorithm is therefore considered a preprocessing task rather than a data cleaning task. Since imputation is less likely to introduce bias into your data than removing missing values, it is generally preferable to impute missing values rather than remove them.
In the rare event that you know what a missing value is supposed to be, the best imputation method is always to replace the missing value with the known “correct” value. However, in the more likely event that you do not know what a missing value is supposed to be, there are many possible approaches that you can take to imputing it. The simplest approaches include constant-value imputation (replacing all missing values with a plausible constant value, such as “0”), mean imputation (replacing all missing values in a column with the average value of the non-missing values in the column), and forward/backward fill imputation (replacing missing values in time-dependent data with the previous or next non-missing value). There are also a range of more sophisticated model-based approaches to imputation, but we will not discuss them in this book.
If there are multiple plausible ways to impute the data, we encourage you to implement each type of imputation in your preprocessing function (you can include an argument for choosing which imputation technique to use). This will help you easily evaluate and document the impact of any imputation judgment calls on the downstream results.
4.5.2.1 Suggested Examination
The explorations in Box box-identify-missing can help identify ambiguously formatted missing values as well as the extent of missing values in the data. Note that there is some overlap between these explorations and those for identifying invalid values.
4.5.2.2 Possible Action Items
Data cleaning action items for missing values primarily involve ensuring that all missing values are explicitly recorded NA (rather than as placeholders such as 999, "unknown", etc.). Some possible action items are described in Box box-action-missing.
While clean data can contain missing values, if you plan to apply algorithms or perform analyses that do not allow missing values, then you may need to create some preprocessing action items to handle missing values. Some possible action items are described in Box box-action-missing-preprocess.
We generally recommend removing columns with many missing values or imputing missing values over removing rows with missing values, since (as mentioned previously) removing rows (observations) is more likely to introduce bias into your data.
Note that while some algorithms may appear to allow data with missing values, they are often just removing all rows with missing values under the hood (i.e., without indicating that they have done so). To ensure that you know exactly how missing values are being handled in your analysis, we recommend handling them yourself during preprocessing rather than leaving that task to an algorithm.
4.5.2.3 A Note on Imputing Missing Values
If you decide to impute missing values by replacing them with plausible nonmissing values, then your goal should be to try to strengthen the relationship between the data and the underlying reality. Keep in mind that it is usually impossible to check that the imputed value is close to the real quantity that it is supposed to represent (although you can demonstrate that your imputation procedure generates predictable results by imputing nonmissing values and seeing how close the imputed values are to the actual reported values).
In general, when imputing missing values, the imputation procedure that you choose will be a judgment call whose options should be based on domain knowledge. All datasets have missing values for different reasons, and as such, they should be treated uniquely.
Unless it is absolutely necessary (or your data contains a lot of observations—at least in the tens of thousands), we don’t recommend imputing variables that have more than half of their values missing. Instead, unless these variables (columns) are particularly important for your analysis, we recommend removing them. There are certainly exceptions to this rule, however. For example, we don’t want to remove the organ donation count variable from our organ donation data (despite over half of the donor counts being missing) because this is our primary variable of interest!
4.5.2.4 Identifying Missing Values in the Organ Donation Data
Let’s conduct these missing value explorations for the organ donation data. The code for this analysis can be found in the “Examining Missing Values” section of the 01_cleaning.qmd (or .ipynb) file organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository. We will focus our missing value explorations just on the TOTAL Actual DD variable.
Recall that the “invalid values” explorations in the previous section did not reveal any strange TOTAL Actual DD values, so to the best of our knowledge, all missing values are already explicitly encoded as NA, and so no cleaning action items are necessary to reformat missing values.
Let’s turn instead to consider the distribution of missing values in the data. Figure fig-missing-proportions shows a bar chart of the number of nonmissing donor count (TOTAL Actual DD) values by year. If all countries reported a donor count every year (i.e., there was no missing data), then each bar should reach a height of 194, since there are 194 countries. There are clearly a lot of missing values in this variable (a quick calculation reveals that almost 60 percent of the TOTAL Actual DD values are missing, and 79 countries never report any donor counts at all). Notice that the number of nonmissing donor counts seems to increase over time and then decrease again after 2015. Does that seem odd to you?
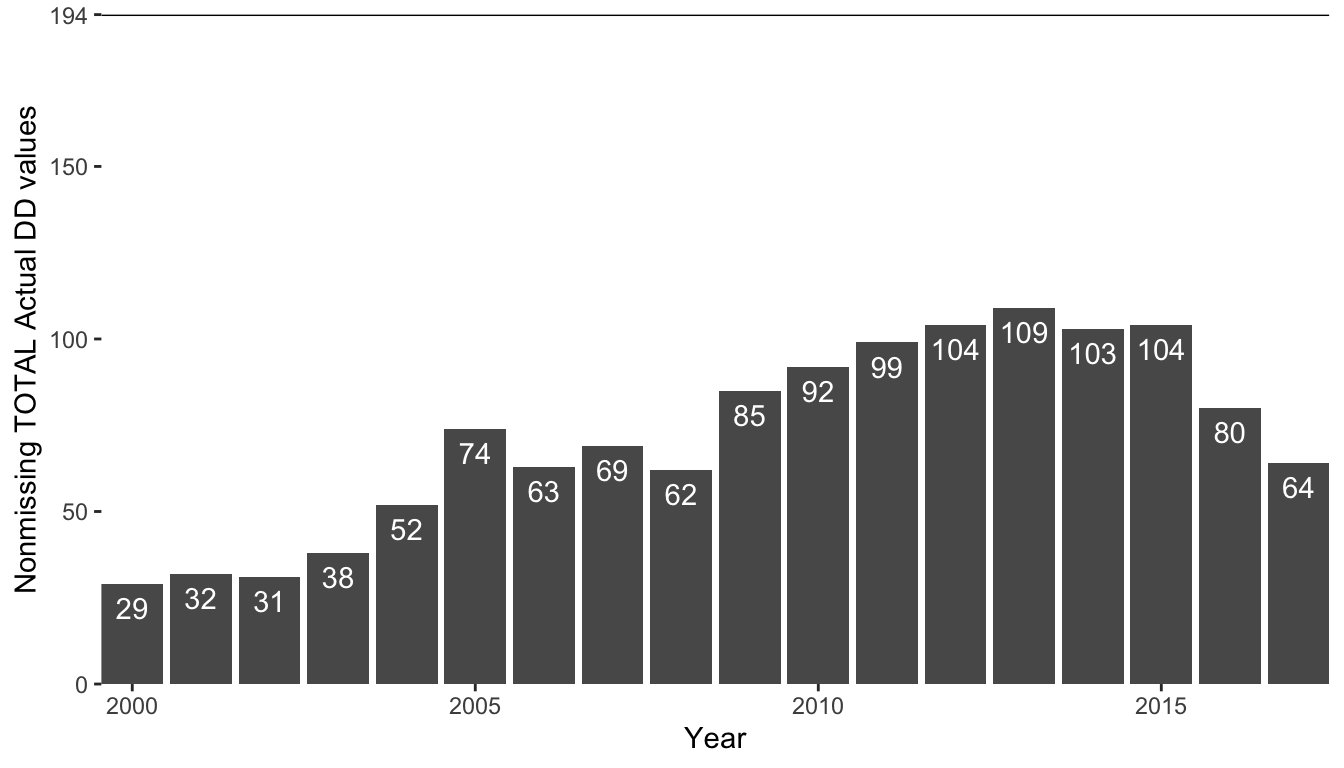
Since part of our analysis will involve investigating global donor trends, if we ignore or remove missing values, we risk underestimating the number of organ donations. Thus, to conduct this analysis, it feels prudent to conduct a preprocessing action item: impute the missing donor counts. The question is how best to impute the donor counts?
Table tbl-peru-data shows the TOTAL Actual DD data for Peru. Notice how some years have missing counts, and others don’t. How would you go about imputing Peru’s missing values? Your critical thinking skills and domain knowledge will come in handy here!
| COUNTRY | YEAR | TOTAL Actual DD |
|---|---|---|
| Peru | 2000 | NA |
| Peru | 2001 | NA |
| Peru | 2002 | NA |
| Peru | 2003 | NA |
| Peru | 2004 | 29 |
| Peru | 2005 | 22 |
| Peru | 2006 | NA |
| Peru | 2007 | NA |
| Peru | 2008 | NA |
| Peru | 2009 | NA |
| Peru | 2010 | 94 |
| Peru | 2011 | 127 |
| Peru | 2012 | 94 |
| Peru | 2013 | 97 |
| Peru | 2014 | 73 |
| Peru | 2015 | 82 |
| Peru | 2016 | 70 |
| Peru | 2017 | 52 |
Since it seems fairly unlikely that Peru simply had no organ donations in 2006–2009, imputing these missing values with 0 would probably not be the best choice. Moreover, since the number of donations in Peru is certainly very different from the number of donations in other countries, imputing these missing values using the average of the donor counts across all countries would also be a poor choice. While we could apply mean imputation based just on Peru’s nonmissing donor counts, this approach would likely overestimate the missing values because it ignores the fact that Peru’s donor counts are increasing over time. So perhaps we can use the donor count information from the surrounding nonmissing years to compute some plausible donor counts for the missing years. Some plausible options4 include imputing a country’s missing values with one of the following:
The previous nonmissing count (0 if there are no previous nonmissing counts).
The average (mean) of the previous and the next nonmissing counts.
Since both approaches seem fairly reasonable, the choice is a judgment call (and we will allow the user to specify their imputation options as an argument in our preprocessing function). Notice how important the role of domain knowledge (i.e., realizing that Peru’s donor rates should not be based on other countries’ donor rates and there is a time dependence in the data) was for arriving at a set of plausible imputation judgment call options.
For the 79 countries that do not report any donor counts, we decided to impute all their missing counts with 0s (based on our domain assumption that these countries had no organ donors, which feels plausible in most, but certainly not all cases).
4.5.3 Messy Data Trait 3: Nonstandard Data Format
The format of your data matters. Computers are not (yet) geniuses. This means that the format of your data needs to match what is expected by the computational algorithms you will apply. Fortunately, most algorithms expect that your data will be in what is called a tidy format.
A tidy dataset satisfies the following criteria:
Each row corresponds to a single observational unit (if the data for a single observational unit is spread across multiple rows, most algorithms will treat these as different observational units).
Each column corresponds to a single type of measurement.
While many datasets will already be in a tidy format, it is helpful to be able to identify when they aren’t. Table tbl-example-rectangular shows the 2016 and 2017 organ donation data for three countries (Australia, Spain, and the US). Notice that although each country has two rows in the data, each observational unit (i.e., each country-year combination) appears only once, and each column corresponds to one type of measurement. This data is thus already in a tidy format.
| COUNTRY | YEAR | TOTAL Actual DD | Actual DBD | Actual DCD |
|---|---|---|---|---|
| Australia | 2016 | 503 | 375 | 128 |
| Spain | 2016 | 2,019 | 1,524 | 495 |
| USA | 2016 | 9,970 | 8,286 | 1,684 |
| Australia | 2017 | 510 | 359 | 151 |
| Spain | 2017 | 2,183 | 1,610 | 573 |
| USA | 2017 | 10,286 | 8,403 | 1,883 |
An alternative format of this data is shown in Table tbl-example-rectangular-long, where there is now a Variable column that specifies which donor variable is being measured (TOTAL Actual DD, Actual DBD, or Actual DCD), and a Value column that specifies the corresponding value for each variable. Each row is still identified by the COUNTRY and YEAR key variables, but there are now three rows for each country-year combination (one for each of the donor variables being measured). Therefore this data is in a long format and is no longer considered tidy (but can sometimes still be useful). See Wickham (2014) for more examples and explanations of this tidy format.
| COUNTRY | YEAR | Variable | Value |
|---|---|---|---|
| Australia | 2016 | TOTAL Actual DD | 503 |
| Australia | 2016 | Actual DBD | 375 |
| Australia | 2016 | Actual DCD | 128 |
| Spain | 2016 | TOTAL Actual DD | 2,019 |
| Spain | 2016 | Actual DBD | 1,524 |
| Spain | 2016 | Actual DCD | 495 |
| USA | 2016 | TOTAL Actual DD | 9,970 |
| USA | 2016 | Actual DBD | 8,286 |
| USA | 2016 | Actual DCD | 1,684 |
| Australia | 2017 | TOTAL Actual DD | 510 |
| Australia | 2017 | Actual DBD | 359 |
| Australia | 2017 | Actual DCD | 151 |
| Spain | 2017 | TOTAL Actual DD | 2,183 |
| Spain | 2017 | Actual DBD | 1,610 |
| Spain | 2017 | Actual DCD | 573 |
| USA | 2017 | TOTAL Actual DD | 10,286 |
| USA | 2017 | Actual DBD | 8,403 |
| USA | 2017 | Actual DCD | 1,883 |
Although the tidy format of our data is dictated by algorithmic expectations, this expectation is more or less universal, so we treat the process of converting the data into a tidy format as a data cleaning task, rather than a preprocessing task. Some algorithms may have additional specific formatting requirements that can be addressed as a preprocessing task.
4.5.3.1 Suggested Examination
Box box-identify-tidy provides some suggested examinations that help identify whether your data has a tidy format.
4.5.3.2 Possible Action Items
Box box-action-tidy provides some common action items that you may need to perform to convert your data into a tidy format.
If you need to convert the data to another format to apply a particular analysis or algorithm, then your reformatting action item will be considered a preprocessing action item rather than a data cleaning action item.
4.5.3.3 Examining the Data Format for the Organ Donation Data
Let’s take a look at the format of the organ donation data. In the organ donation data, there is already a single row for each COUNTRY and YEAR combination (the observational units). There are also no columns that contain multiple types of measurements, so the data is already in a tidy format.
4.5.4 Messy Data Trait 4: Messy Column Names
Datasets often come with ambiguous, inconsistent, and poorly formatted column names, such as column names with spaces in them (computers have a hard time with spaces) or that have inconsistent case (e.g., some variables begin with an uppercase letter, whereas others don’t). Converting column names to a consistent, human-readable, and computer-friendly format makes your life much easier. Your column names should follow the style guide that we referenced in sec-workflow-setup—specifically, they should be lowercase, human-readable, and words should be separated by underscores (like_this).
There are several automated functions for reformatting column names so that they adhere to the style guide (e.g., the clean_names() function from the “janitor” package in R), but these are only helpful when the column names already contain meaningful human-readable words. If your column names do not contain human-readable words, such as HMN.AG (age) and HMN.WT (weight), all that these automated approaches can do is convert them to equally non-human-readable (but neatly formatted) versions, such as hmn_ag and hmn_wt. Therefore, some datasets will require you to manually (using code) rename each column to make them human-readable (e.g., renaming HMN.AG to age and HMN.WT to weight).
When you have a large dataset with dozens or even hundreds of columns, this can be a very time-consuming task. However, it can also be a hugely informative task because it forces you to explicitly acknowledge every individual column in your data (and is, therefore, a much more effective means of learning what variables your data contains than just skimming the data dictionary). If you do manually (using code) rename the columns in your data, be sure that your code is written so that it is clear how the old column names are connected to the new column names.
The examination for identifying messy column names is to simply print the column names, and the obvious action item is to modify them.
4.5.4.1 Examining the Column Names for the Organ Donation Data
Let’s take a look at the column names for the organ donation data. The variable names in the organ donor data (Table tbl-organs-random) are very inconsistent (e.g., some words are capitalized and some aren’t) and are not particularly human-readable. Thus we will add a data cleaning action item: clean the column names manually where, for example, TOTAL Actual DD will become total_deceased_donors, Actual DBD will become deceased_donors_brain_death, and Actual DCD will become deceased_donors_circulatory_death. These column names are quite long, and you might prefer to use shorthand versions, but whatever you choose, it is important that they are easily human-readable.
4.5.5 Messy Data Trait 5: Improper Variable Types
In R, each variable will typically be formatted as one of the following types:
Numeric: Each entry is a number. If your variable has a numeric type, you can do mathematical operations with it. Examples include the donor count variables.
Binary: Each entry is one of two values that are usually coded as
TRUE/FALSEbut are sometimes formatted numerically as0/1or categorically as"Yes"/"No".Character (text): Each entry is free-form text, where there is no fixed set of options to which each entry must belong.
Categorical: Each entry is one of a finite set of categories (levels). An example is the
COUNTRYvariable in the organ donation data. Categorical variables are sometimes formatted as characters, and vice versa.
There are a few special types of variables that you might encounter, such as date or datetime variables, as well as more specific types of numeric variables (such as doubles, integers, etc.). Equivalent types also exist in Python.
4.5.5.1 Suggested Examination
Examinations for identifying the type of each variable are described in Box box-identify-type. If the type of a variable is different from what you expect (based on your knowledge of the data as well as domain knowledge), then this might indicate that there are some incorrectly formatted entries in the data that are forcing the variable to be a particular type. For example, if a column containing numbers has a character type, this might indicate that there are some nonnumeric entries in the column.
4.5.5.2 Possible Action Items
The most likely action items for cleaning improper variable types involve converting variables from one type to another. Examples include converting dates stored as characters to date types and converting numbers stored as characters to numeric types. Always check that your conversion did what you expected.5
Sometimes the choice of variable type will depend on the particular analysis that you want to conduct. For instance, some numeric variables might be better formatted as categorical variables (such as ZIP codes), and categorical variables with ordered levels (such as “good,” “great,” and “excellent”) might be better formatted numerically so that the computer will correctly interpret the ordering (replacing “good” with 1, “great” with 2, and “excellent” with 3). Some analyses may also require that you simplify categorical variables by aggregating uncommon/rare levels of categorical variables. When performed with a particular analysis or algorithm in mind, variable type conversions and modifications are considered preprocessing action items rather than data cleaning action items. Common action items for cleaning or preprocessing variable types are described in Box box-action-type.
4.5.5.3 Identifying the Type of Each Variable in the Organ Donation Data
Let’s consider the variable types of the organ donation data. All the columns in our organ donation data are numeric, except for COUNTRY and REGION, which are categorical (but are stored as characters). These seem like appropriate types and so we don’t introduce any action items. See the “Assessing Variable Type” section of the 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository for an analysis.
4.5.6 Messy Data Trait 6: Incomplete Data
A complete dataset is one in which each observational unit is explicitly represented in the data. For the organ donation data, this would mean that every country and year combination (i.e., every observational unit) exists in the data, even if those rows are filled with missing values.
Why does it matter if our data is complete? Imagine that you want to calculate the total number of global organ donations. If some years of data are absent for some countries, then these years won’t be included in your computation, even if you impute missing values. The problem is that you might not realize that these rows are missing. Even missing value explorations won’t uncover these missing rows, because rather than containing missing values, they simply don’t exist.
4.5.6.1 Suggested Examination
Identifying whether your data is complete involves understanding which columns uniquely identify the observational units and identifying how many observational units your data should contain. If there is a mismatch between the number of rows in your (tidy) dataset and the number of observational units that your data should contain (e.g., determined based on the data documentation), this may indicate that your data is not complete. Box box-identify-complete displays several techniques for identifying whether a dataset is complete.
4.5.6.2 Possible Action Items
If your data is not complete, but you know which observational units are missing, you should complete the data by adding in the missing rows (and filling them with missing values where necessary). Common action items for cleaning or preprocessing incomplete datasets are described in Box box-action-complete.
4.5.6.3 Examining the Completeness of the Organ Donation Data
Let’s conduct these completeness examinations for the organ donation data. Recall that there are a total of \(3,165\) rows in the data and a total of 194 countries. However, since the data spans from 2000 to 2017 (a total of 18 years), the data would contain \(18 \times 194 = 3,492\) rows if it were complete. Since \(3,165 \neq 3,492\), our data is clearly not complete!
To try to determine which observational units are missing, Figure fig-countries-by-year presents a bar chart of the number of rows in the data for each year (note that the similar chart in Figure fig-missing-proportions displayed the number of rows with nonmissing TOTAL Actual DD entries—Figure fig-countries-by-year includes rows with missing values).
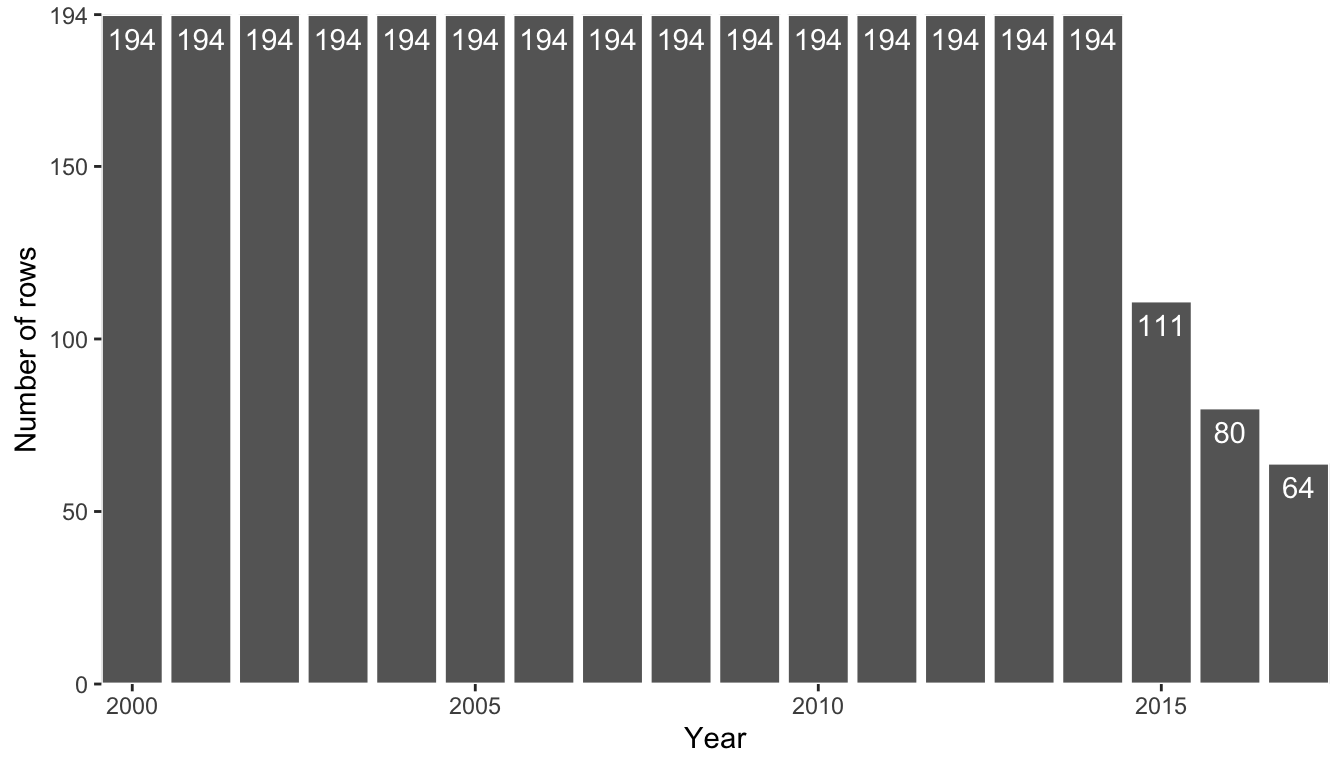
From Figure fig-countries-by-year, the data appears to be complete until 2014 but is not complete afterward (some countries seem not to exist in the data past 2014). This is actually quite a surprising finding that we could have easily missed had we not conducted such a thorough exploration of our data. Moreover, failing to notice this finding may have derailed our downstream analyses.
Why do some countries not provide data after 2014? Unfortunately, since we aren’t in touch with the people who collected the data, all we can do is hypothesize. Further exploration of the data indicates that the reason is related to a change in how missing values are reported after 2014. For a detailed exploration and discussion, see the “Examining Data Completeness” section of the 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository, part of which is left as an exercise (exercise 22) at the end of this chapter.
Based on our findings, we will add a data cleaning action item: complete the data by adding the country-years whose rows are absent and populate their entries with missing values. If you are also conducting any imputation, you should implement your imputation step after completing the data so the missing values we add will be filled in.
4.5.7 Addressing Any Remaining Questions and Assumptions
If, after completing the suggested explorations given here, there are any remaining questions that have not been answered or assumptions that you made that have not been checked, be sure to do so now. For instance, in our explorations of the organ donations data given here, we found an answer as to why the number of rows did not match what we expected (the data was not complete), but we did not determine whether the TOTAL Actual DD variable corresponds to the sum of the Actual DCD and Actual DBD (a question asked in Step 1 of our data cleaning procedure). The goal of the explorations was not just to address the set of general issues that commonly arise, but also to identify any additional data-specific issues that will be unique to your dataset. You can either address each data-specific question and assumption as it arises, which is what we do in the 01_cleaning.qmd (or .ipynb) file in the organ_donations/dslc_documentation/ subfolder of the supplementary GitHub repository—see sections labeled as “[problem-specific]”; or you can document them so that you can address them after you have finished your general investigations.
4.6 Step 4: Clean the Data
Cleaning the data involves implementing the data cleaning action items that we identified in Steps 1–3 of our data cleaning workflow.
Recall that unless your cleaning process will be particularly computationally intensive, we do not recommend saving a copy of your clean datasets to load for your analysis. Instead, we recommend writing a data cleaning function whose input is the raw data and whose output is the clean data (and whose arguments allow you to create alternative versions of the clean data using different cleaning judgment calls). This function, which you can save in a .R file (if using R) or .py file (if using Python) in the functions/ subdirectory, can then be “sourced” and used to clean the raw data in each analysis document without requiring you to copy and paste your cleaning code. By creating a data cleaning function, you are making it easy to create several alternative versions of the cleaned data for performing stability analyses of your downstream results.
As an example, the following code is an example of an R function that prepares (cleans and preprocesses) the organ donation dataset and allows alternatives for two judgment calls: (1) remove_pre_2007 (if TRUE, the function will remove the pre-2007 survey data, and if FALSE, the default value, it will not); and (2) rescale_population (if TRUE, the default value, the function will multiply the population variable by 1 million, and if FALSE, it will not).
prepareOrganData <- function(data,
remove_pre_2007 = FALSE,
rescale_population = TRUE,
...) {
if (remove_pre_2007) {
# code that removes the pre-2007 data
data <- data %>%
filter(year >= 2007)
}
if (rescale_population) {
# code that multiplies population by 1 million
data <- data %>%
mutate(population = population * 1000000)
}
# code for other action items
...
return(data)
}Such a function can then be used to create multiple different cleaned/preprocessed versions of the data. For example, to create a version of the prepared dataset that removed the pre-2007 data but did not rescale the population variable, you can simply call the prepareOrganData() function with the relevant arguments:
organs_clean <- prepareOrganData(organs_original,
remove_pre_2007 = TRUE,
rescale_population = FALSE)Recall that it is up to you whether you write a separate function for data cleaning (e.g., cleanOrganData()) and preprocessing (e.g., preprocessOrganData()), but it is often easier to write a single function that performs both (we refer to the process of both data cleaning and preprocessing as data preparation, and in our example above, we called the combined cleaning/preprocessing function prepareOrganData()).
4.6.1 Cleaning the Organ Donation Data
The data preparation function that we created lives in the prepareOrganData.R (or .py) script which can be found in the organ_donations/dslc_documentation/functions/ subfolder of the supplementary GitHub repository, and it is also shown in the 01_cleaning.qmd (or .ipynb) file.
As a summary, the data cleaning action items (including alternative judgment calls, where relevant) that we implemented for the organ donation data were as follows:
Multiply the population variable by 1 million so that it has the correct scale.
Remove the pre-2007 data (judgment call: the default option is not to remove the pre-2007 data).
Convert the column names to more human- and computer-friendly versions. For instance,
COUNTRYbecomescountry, andTOTAL Actual DDbecomestotal_deceased_donors.Complete the dataset by adding the rows that are absent from the data after 2014 (and populate their entries with
NAs).
We also implemented the following preprocessing action item
- Impute the missing donor counts with plausible nonmissing values. We implemented two alternative imputation techniques (previous or average) as discussed in sec-organs-missing.
4.7 Additional Common Preprocessing Steps
While this chapter focused on developing data cleaning action items, many algorithms will require us to implement additional specific preprocessing action items. For instance, some algorithms will accept only numeric variables (requiring us to convert all categorical variables to numeric formats), and some will assume that each variable is on the same scale. Common examples of additional preprocessing steps might include:
Standardizing or normalizing variables that are on different scales so they are comparable (see sec-comparability in sec-eda)
Transforming variables so they follow a more Gaussian (“normal” bell curve) distribution (see sec-pca-transformation in sec-dimension-reduction)
Splitting categorical variables into binary variables, called “one-hot encoding” in ML (see sec-dummy in sec-ls-adv)
Featurization (creating new variables from the existing variables)
We will discuss these preprocessing techniques throughout this book as they arise in the context of algorithmic applications.
Exercises
True or False Exercises
For each question, specify whether the answer is true or false (briefly justify your answers).
Data cleaning is an optional part of the DSLC.
You should avoid modifying the original data file itself; instead, you should try to modify it only within your programming environment.
A clean dataset can contain missing values.
A preprocessed dataset can contain missing values.
The best way to handle missing values is to remove the rows with missing values.
The set of valid values for a variable is usually determined based on domain knowledge and how the data was collected.
An unusual or surprising value should be treated as invalid.
There is a single correct way to clean every dataset.
It is generally recommended that you split your data into training, validation, and test sets before cleaning it.
You should avoid exploring your data before you clean it.
You must write separate cleaning and preprocessing functions.
A different preprocessing function is needed for each algorithm that you apply.
Conceptual Exercises
What do you think might be a possible cause of the missing values in the organ donation dataset discussed in this chapter?
How can writing a data cleaning/preprocessing function help with conducting a stability analysis that assesses whether the data cleaning/preprocessing judgment calls affect the downstream results?
Why it is not a good idea to try to automate the process of data cleaning (i.e., to create a general one-size-fits-all set of data cleaning tasks)?
What is the difference between data cleaning and preprocessing?
Suppose that your job is to prepare a daily summary of the air quality in your area. To prepare your report each day, you consider the set of air quality measurements collected each day at 8 a.m. from a set of 10 sensors, all within a 20-mile radius of one another. Today, nine of the 10 sensors reported an Air Quality Index (AQI) within the range of 172–195 (very unhealthy), but one of the sensors reported an AQI of 33 (good).
Would you consider this individual sensor’s measurement to be invalid? Is there any additional information that might help you answer this question?
If you learned the sensor was broken, what, if any, action items would you introduce to handle this data point? Justify your choice.
The following two line plots show the total number of organ donations worldwide (computed as the sum of the donor counts from all countries) by year based on (a) the original version of the organ donation data where we have not completed the data or imputed the missing donor counts; and (b) a preprocessed version of the data where we have both completed the data (by adding in the missing rows) and imputed the missing donor counts (using the “average” imputation method described where we replace a country’s missing donor count with the average of the previous and the next non-missing donor counts for that country).
Explain why preprocessing the data by completing it and imputing the missing donor counts changes the result shown in the figure.
How does the takeaway message of plot (a) differ from plot (b)? Discuss the cause of these differences.
Which version, (a) or (b), do you think is a better reflection of reality?

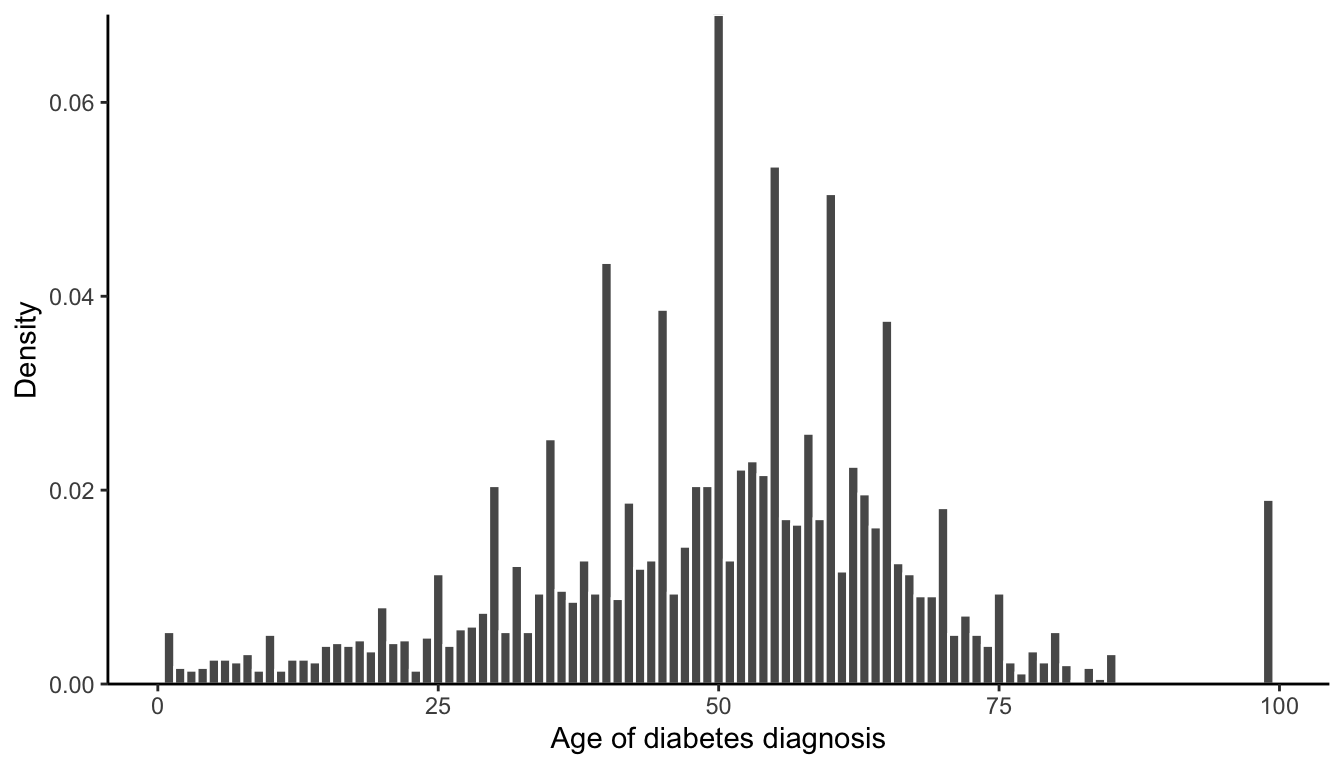
The histogram here shows the distribution of the reported age of diabetes diagnosis of a random sample of American diabetic adults collected in an annual health survey, called the National Health and Nutrition Examination Survey (NHANES), conducted by the Centers for Disease Control and Prevention (CDC).
Identify two strange or surprising trends in this histogram. What do you think is causing these trends?
Describe any data cleaning action items you might create to address them.
The table here shows a subset of the data on government spending on climate and energy, with the type of each column printed beneath the column name.
What are the observational units?
Is the data in a tidy format?
Mentally walk through the data cleaning explorations for this data and identify at least two action items that you might want to implement to clean this data. Document any judgment calls that you make and note any alternative judgment calls that you could have made.
Create one possible clean version of this dataset (you can just manually write down the table—that is, you don’t need to use a computer, but you can if you want to).
|Year (numeric) |Type (categorical) |Spending (character) | |:————-|:—————–|:——————-| |2013 |Energy |“$15,616” | |2013 |Climate |“$2,501” | |2014 |Energy |“$17,113” | |2014 |Climate |“$2,538” | |2015 |Energy |“$19,378” | |2015 |Climate |“$2,524” | |2016 |Energy |“$20,134” | |2016 |Climate |“$2,609” | |2017 |Energy |“$19,595” | |2017 |Climate |“$2,800” |
Reading Exercises
- Read “Tidy Data” by Hadley Wickham (2014) (available in the
exercises/readingfolder on the supplementary GitHub repository).
Coding Exercises
- Work through the organ donation cleaning code provided in the
01_cleaning.qmd(or equivalent.ipynb) file in theorgan_donations/dslc_documentation/subfolder of the supplementary GitHub repository. In this exercise, your task is to complete the “Examining Data Completeness” section of this file by conducting some explorations to try to understand why the data is no longer complete after 2014 and summarize your findings (the only donor count variable that you need to consider isTOTAL Actual DD).6
Project Exercises
[Non-coding project exercise] IMAGENET is a popular public image dataset commonly used to train image-based ML algorithms (such as algorithms that can detect dogs and cats in images). The goal of this question is to guide you through conducting Step 1 (Learning about the data collection process and the problem domain) of the data cleaning procedure described in this chapter using the information provided on the IMAGENET website and the Kaggle website. Note that the dataset, which is available on Kaggle, is more than 100 GB–you do not need to download it to answer this question.
How was the data collected (e.g., how did they find the images and decide which ones to include)?
How have the images in the dataset been cleaned or reformatted?
How would you plan to assess the predictability of an analysis conducted on this data (e.g., do you have access to external data? Would you split the data into training, validation, or test sets? Would you use domain knowledge?)
Write a summary of how easy it was to find this information, any other relevant information that you learned, and any concerns you have about using algorithms that are based on this dataset for real-world decision making.
Re-evaluating growth in the time of debt For this project, you are placing yourself in Thomas Herndon’s shoes. Your goal is to try and reproduce the findings of Reinhart and Rogoff’s study (introduced in sec-workflow-setup) using historical public debt data (debt.xls) downloaded from the International Monetary Fund (IMF), as well as gross domestic product (GDP) growth data (growth.csv) downloaded from the World Bank.
These data files can be found in the
exercises/growth_debt/data/folder in the supplementary GitHub repository.The file debt.xls contains the IMF data on the annual debt as a percentage of GDP data from 1800 to 2015 (a total of 216 years) for 189 countries.
The file growth.csv contains the World Bank data from 1960 through to 2021 (a total of 62 years) for 266 countries.
A template for the
01_cleaning.qmdfile for R (or equivalent.ipynbfiles for Python) has been provided in the relevantexercises/growth_debt/folder in the supplementary GitHub repository.Fill in the template
01_cleaning.qmd(or equivalent.ipynb) file by implementing steps 1-3 of the data cleaning process outlined in this chapter. We recommend filtering the debt.xls data to 1960 and beyond and exploring the two data files (debt.xls and growth.csv) separately.To implement step 4 of the data cleaning process, write a separate cleaning function for each dataset. Your debt-cleaning function should create a clean debt dataset whose rows for Australia from 1960–1969 look like the left table below, and your growth-cleaning function should create a clean growth dataset whose rows for Australia from 1960–1969 look like the right table below:
country year debt_pct_gdp Australia 1960 31.47 Australia 1961 30.31 Australia 1962 30.42 Australia 1963 29.32 Australia 1964 27.65 Australia 1965 NA Australia 1966 41.23 Australia 1967 39.25 Australia 1968 38.21 Australia 1969 35.73 country year growth_pct_gdp Australia 1960 NA Australia 1961 2.483271 Australia 1962 1.294468 Australia 1963 6.214949 Australia 1964 6.978540 Australia 1965 5.980893 Australia 1966 2.381966 Australia 1967 6.303650 Australia 1968 5.095103 Australia 1969 7.043526 - Write a pre-processing function that takes as its input the two clean datasets and then joins them together by country and year. The rows for Australia from 1960–1969 in your single combined dataset should look like the following table. Note that the country names are not identical across each dataset, so you will need to decide how to handle country names that do not match (e.g., you might want to manually modify those that are spelled differently and remove those that are not actual countries).
country year debt_pct_gdp growth_pct_gdp Australia 1960 31.47 NA Australia 1961 30.31 2.483271 Australia 1962 30.42 1.294468 Australia 1963 29.32 6.214949 Australia 1964 27.65 6.978540 Australia 1965 NA 5.980893 Australia 1966 41.23 2.381966 Australia 1967 39.25 6.303650 Australia 1968 38.21 5.095103 Australia 1969 35.73 7.043526
References
Wickham, Hadley. 2014. “Tidy Data.” Journal of Statistical Software 59 (1): 1–23.
In big collaborative projects it is often unrealistic for each person to involve themselves in every part of the DSLC. Instead, it is common for each person’s role to focus on one specific part, such as preparing the data, presenting it, or training machine learning (ML) algorithms.↩︎
We only show the first 7 columns due to page space constraints.↩︎
This survey was originally downloaded from http://www.transplant-observatory.org/questionnaire-pdf/.↩︎
Other options include imputing using the closest (in terms of year) nonmissing count or an interpolated count value that takes into account the trend from all the nonmissing values from the country.↩︎
For example, in R, if you try to convert a character directly to a numeric using the
as.numeric()function, it will be converted toNA.↩︎As a hint, try counting the number of missing values in the
TOTAL Actual DDvariable each year and comparing it with the number of rows each year.↩︎